How It's Made
Adopting dbt as the Data Transformation Tool at Instacart

By James Zheng
At Instacart, datasets are transformed for use in analytics, experimentation, machine learning, and retailer reporting. We use these datasets to make key business decisions that provide better experiences for our customers and shoppers and to share critical business metrics with our retailers. Data transformation is a crucial step that curates raw data into a consumable format. In early 2022, our Data Infrastructure team decided to explore and adopt Data Build Tool (dbt), as the standard data transformation tool for Snowflake datasets. This article details our deployment of dbt and the techniques that enable dozens of teams to run thousands of dbt models at scale.
Motivation
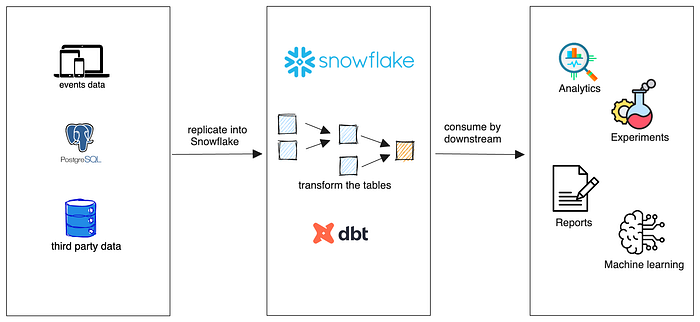
At Instacart, Snowflake serves as our primary data warehouse. Initially, data is replicated into Snowflake tables from multiple sources: Postgres databases, application events, and third-party vendors. Once the tables are available, users may write SQL transformation queries to format the tables to better suit their particular needs.
Our data’s volume grew exponentially since the beginning of the pandemic in 2020. By 2022, we had more than 5 million tables and 10+ petabytes of data in Snowflake. Various teams at Instacart concurrently created their own versions of the data transformation tool to address their use cases. At the time, we relied on more than three different tools to transform data, forcing the Data Infrastructure team to face the following challenges:
- Tooling fragmentation and inconsistent techniques: Users and Infrastructure engineers become less productive as they have to learn and maintain multiple tools. The development process varies from tool to tool.
- Lack of modularity: The SQL queries are thousands of lines long and not reusable which makes them impossible to maintain and expensive to rerun.
- Measuring and tuning query performance at scale: Because there is no consistent way to extract insights, it is difficult to scale and improve query performance.
dbt+Airflow as a data transformation tool
dbt is an open source, industry-standard tool. It allows users to write SQL transformation logic in a modularized style and provides a command line tool to execute the queries. Out of the box, it offers rich features superior to our existing tools. This enables our users to adopt new techniques that improve their productivity and the Infrastructure team to enforce standardizations.
Once queries are written in dbt format, the dbt commands need to run periodically to maintain data freshness. To solve this, we bring Apache Airflow into the tech stack. Similar to our philosophy of adopting dbt, Airflow is also an open source and industry-standard orchestration tool. Choosing Airflow was an easy decision because it was already a familiar and scalable system at Instacart.
Architecture
To start, we installed the dbt command line tool and initiated a dbt project inside a GitHub repository, instacart-dbt. This repository stores all of the SQL transformation queries. To onboard, our users clone the instacart-dbt repository, download the dbt tool, and start writing dbt code.
Then we created another repository for Airflow. We launched the Airflow cluster using an in-house Terraform module built by a separate team. The Airflow cluster was deployed to AWS as an ECS cluster; each Airflow component can be independently scaled.
To tie dbt and Airflow together, we leveraged Buildkite to validate and publish dbt metadata, like the manifest.json, to S3. On the Airflow side, we wrote a DAG generation script that reads from the S3 metadata and constructs the DAGs, Directed Acyclic Graphs. A DAG consists of all the inter-dependencies required to build a data pipeline.
Let’s go through each of the steps required to build a data pipeline in dbt+Airflow.
Step 1.
Users write a SQL transformation query in dbt format.
Users write a configuration file to schedule the execution of this pipeline.
owner: james.zheng
start_date: 2023–03–27
schedule_interval: 0 1 * * *
deploy_env: dev, prod
models:
— name: users_and_orders
A configuration that instructs Airflow to build the users_and_orders model in the development and production environments and executes daily at 1 am.
Steps 2, 3.
Buildkite, our continuous integration and deployment platform, runs validation and then compiles and uploads the dbt code, configuration files, and dbt’s manifest.json to S3.
Step 4.
The Airflow Scheduler downloads the pipeline configuration from S3 and generates the DAGs.
Step 5.
Based on the schedule of the pipeline, the Airflow Worker runs the dbt command that builds the table in Snowflake.
How does dbt+Airflow solve the aforementioned problems?
- Tooling fragmentation and inconsistent development practices
- Lack of modularity
- Lack of ability to measure and tune query performance at scale
Solving Tooling Fragmentation and Inconsistent Development Practices
Initially, there was no standard development process among the legacy transformation tools. Some tools have two environments while others have only a production environment. We wanted our transformation tool to be consistent with the environments of other software systems and services at Instacart. As a result, we required three environments–local, development, and production–in dbt for every team. At the same time, the setup should provide enough flexibility such that each team can choose their tables’ destination for each environment, which we achieved through the use of dbt targets.
Leverage dbt targets to support x teams in y environments.
A dbt target is a block of configuration that specifies the Snowflake connection details. When a new team onboards to dbt, we create three dbt targets in profile.yml, one per environment and a different schema destination per environment.
finance_local:
database: SANDBOX_DB
schema: {{ env_var('DBT_USERNAME') }}
finance_dev:
database: INSTADATA_DEV
schema: ETL_FINANCE
finance_prod:
database: INSTADATA
schema: ETL_FINANCE
Example template in profile.yml for onboarding the finance team onto dbt in three environments.
One of the dbt target, _local, is for users to test changes on their machine. Users require to do a one time provisioning of a schema, named after their username, and start writing a dbt model then test it by running
dbt run -select item_tax -target finance_local
which builds the table in SANDBOX_DB.USERNAME.ITEM_TAX
Once the users are confident in their changes they write a configuration file and provide their team’s profile.
owner: james.zheng
schedule_interval: 0 0 * * *
profile: finance
deploy_env: dev, prod
models:
name: item_tax
When the code is deployed, Airflow will run the dbt command with the target specified by the configuration file.
Airflow in the development environment builds the table INSTADATA_DEV.ETL_FINANCE.ITEM_TAX by executing
dbt run -select item_tax –target finance_dev
Airflow in the production environment builds the table INSTADATA.ETL_FINANCE.ITEM_TAX by executing
dbt run -select item_tax –target finance_prod
This approach enables us to onboard teams quickly and guide teams to build tables in the same set of environments. From the Data Infrastructure team’s perspective, we have a holistic view of all the teams and their schemas in a single configuration file, profile.yml.
Solving the Lack of Modularity
A big advantage of using dbt is that queries are written as modular models. A dbt model is a SQL file that maps to a table in Snowflake. The modularity enables us to capture metrics with table-level granularity. dbt also provides information regarding the inter-model dependencies in a file called manifest.json. Let’s explore how we leverage the manifest.json.
Dynamically generate dependencies in Airflow
In Airflow, a Directed Acyclic Graph (DAG) consists of tasks and their sequences of execution. Our DAG generation script creates one DAG per configuration file. It uses the models field in the configuration file as the most downstream task and traverses the parent_map field in the manifest.json to create the upstream tasks: users and orders. In this process, dbt test tasks are also generated, but for simplicity we will omit this aspect from the examples below.
owner: james.zheng
start_date: 2022–10–04
schedule_interval: 0 * * * *
deploy_env: dev, prod
models:
— name: users_orders
Caption: A configuration to build the users_orders model.
{
"parent_map": {
"model.instacart.users_orders": [
"model.instacart.users",
"model.instacart.orders"
]
}
}
Caption: A manifest.json generated by running the dbt compile command.
Previously, queries to build tables for one data pipeline were all cluttered into one giant SQL file and tables could only be built sequentially. By having dbt models as separate tasks in Airflow, tables like users and orders can be built in parallel. Since Airflow retries at the task level, we also noticed savings on compute cost for a table that fails toward the end of the pipeline.
Following the example above, assume each task takes two hours to complete. We can realize the following improvements: successful pipelines will run faster and retries can occur without rerunning the entire DAG.
+--------------------------------+-------------------+---------------+
| Before | Before | After |
+--------------------------------+-------------------+---------------+
| End-to-end latency | 6 hours (2+2+2) | 4 hours (2+2) |
| Time wasted when retry 3 times | 12 hours((2+2)*3) | 4 hours (2+2) |
+--------------------------------+-------------------+---------------+
Extract metrics from manifest.json
Besides leveraging the manifest.json to build the DAG dependencies, we also extracted useful insight about the codebase. We have a job that parses the manifest.json and exports the result in a Snowflake table. At any time we can see the growth of dbt pipelines and the proportion of models by materialization type.
Today, our dbt+Airflow system supports 100 users, stores 3000 dbt models, and runs 400 pipelines (DAGs) and 5000 unique Airflow tasks in production. At peak, Airflow runs 100 concurrent tasks.
Solving the ability to measure and tune query performance at scale
As the number of dbt models grew, we started to face performance bottlenecks and a spike in Snowflake costs. To start troubleshooting we required visibility into query performance metrics. In this section, we describe how to leverage dbt macros to tag queries and tune our infrastructure to optimize performance and scalability.
Overwriting the set_query_tag macro to tag queries
In Snowflake a query can be tagged so that its metadata will be available in the query history. Fortunately, dbt has an internal macro, set_query_tag, that runs at the beginning of every query. We overwrote the set_query_tag macro to extract variables from the command line and pass them into the Snowflake tags.
{% macro set_query_tag() %}
{% set model_name = model.get('unique_id', '') %}
{% set owner = var('owner', '') %}
{% set dag = var('dag', '') %}
…
{% set query_tag_dict = {
'model_name': model_name,
'owner': owner,
'dag': dag,
...
%}
{% do run_query("alter session set query_tag='{}'".format(query_tag)) %}
{% endmacro %}
Once the macro is written, Airflow runs the dbt command with the following variables:
dbt run --select users --vars {"dag": "users_and_orders", "owner": "james.zheng", …}
By parsing the Snowflake query history and joining with a cost estimation table, a separate pipeline built in dbt, we can answer the following questions with table-level granularity:
- How many queries are involved in creating a table?
- What is the total cost to build tables by: owner, pipeline, environment, warehouse?
- Are long-running models materialized incrementally?
With these insights, we redesigned and improved the way we utilize Snowflake warehouses.
Creating get_snowflake_warehouse macro to route queries to a different warehouse
When looking at the query performance and warehouse costs, we discovered the following issues for queries running on inappropriately sized Snowflake warehouses:
- A light query running on a large warehouse triggers a cold start on the machines, resulting in a 20–40% additional Snowflake compute cost.
- A heavy query running on a small warehouse causes remote disk spillage and performance degradation. These queries run for a long time, causing severe queueing in the Snowflake warehouse.
- A single Snowflake warehouse cannot be tuned to optimally handle a mixture of light and heavy queries.
- A high MAX_CONCURRENCY_LEVEL is better for running many light queries.
- A low MAX_CONCURRENCY_LEVEL is better for running fewer heavy queries.
To accommodate for the growth of dbt models, a naive design is to provision a large Snowflake warehouse per team. However, as mentioned above, if the warehouse runs on low capacity, the cold start contributes to 20%-40% of the total warehouse cost. Another way to interpret this is that for every five teams, we are paying one to two warehouses just to start up and shut down!
Instead, we introduce a design that assigns models to Snowflake warehouses based on their execution times.
The process is:
- Provision a suite of warehouses, one warehouse per size, with a short query timeout=2 hours across all warehouses. For example: DE_DBT_LARGE_WH, DE_DBT_XLARGE_WH, DE_DBT_XXLARGE_WH… These warehouses have different settings for MAX_CONCURRENCY_LEVEL.
- All DBT queries use the medium warehouse by default. This reduces the cost of cold starts.
- Heavy models should be manually configured to run on larger warehouses. This reduces remote disk spillage.
- When a query timeout occurs in the medium warehouse, users should either optimize their model or reassign it to a larger warehouse.
- To handle a growing number of queries on each warehouse, we can horizontally scale by increasing the MAX_CLUSTER_SIZE setting.
The implementation starts with creating the macro get_snowflake_warehouse to enable warehouse configurability at the model level:
{% macro get_snowflake_warehouse(snowflake_warehouse_override) %}
-- Local development always uses hard-coded warehouse in profile.yml
{% if target.name.endswith(‘_local’) %}
{{ return(target.warehouse) }}
{% else %}
{{ return(snowflake_warehouse_override) }}
{% endif %}
{% endmacro %}
Caption: A dbt macro that computes and returns the appropriate warehouse.
In the model configuration block, users explicitly provide the warehouse:
{{
config(
materialized = 'table',
snowflake_warehouse=get_snowflake_warehouse('DE_DBT_XXLARGE_WH')
)
}}
SELECT
...
FROM
...
Caption: An example of using the get_snowflake_warehouse macro in a model configuration.
At this point, our models are tagged and we can run them in different warehouses. To optimize the queries at scale we can inspect the disk spillage per model and automatically send notifications to encourage teams to either bump up the warehouse size or convert a full materialized model to an incremental model.
The shared warehouse design optimizes compute cost without sacrificing configurability and scalability. Another benefit is a cleaner separation of responsibilities between dbt users and Infrastructure engineers. dbt users are responsible for optimizing their queries while Data Infrastructure engineers can focus on monitoring and optimizing the Snowflake warehouses.
Lessons Learned
It took us a year to incorporate dbt into Instacart. Our platform now supports more than 3000 dbt models in production! It was a very rewarding journey and we would like to highlight some learnings that accelerated our success:
- Create a sandbox environment for users: Allows users to test and iterate quickly and reduces the time to troubleshoot in production.
- Provide self-serve tooling with strong CI checks: Improves adoption speed by allowing users to have full control of their models while mitigating production issues.
- Don’t think of a feature in isolation. Prioritize features that unlock other features: For example, the query_tagging feature enables us to extract valuable insights that lead to redesigning how we use Snowflake warehouses.
What is on the Roadmap?
Data transformation is vital to any data-driven business. However, the lack of standard tools results in increased overhead and elevated costs. Now dbt and Airflow can address multiple use cases efficiently while providing all the aforementioned benefits. This is just the beginning of our dbt adoption journey and we plan to improve the system by:
- Standardizing on dbt by migrating and deprecating pipelines from other tools.
- Improving data quality by leveraging dbt tests.
- Improving data discoverability by integrating with Amundsen, an open-source data discoverability and metadata service.
- Improving backfilling for multi-terabyte models by automating and running them in smaller intervals.
Acknowledgments:
Adopting dbt at Instacart for hundreds of users is not just about writing code and calling APIs. The one-year journey involved a multifaceted process of cross-team collaboration, constant feedback and adjustments, a variety of user training video and documentation, and rigorous infrastructure improvements.
A special thanks to the Data Infrastructure team members Wendy Ouyang, Ayush Kaul, Anant Agarwal, Sean Cashin, Doug Hyde, Ana Lemus and Nate Kupp for building and continuing to support this project at Instacart. We would also like to extend our gratitude to the early dbt adopters who provided valuable feedback, and engineers from other teams that helped integrate dbt with other services.
We would like to thank you all for expressing interest in data transformation. We hope that you learned about the data challenges and solutions at Instacart, and find this to be helpful in your own data journey. Please don’t hesitate to share your thoughts below — we’re eager to hear what you think! Stay tuned for the next part of this series!
Instacart
Author
Instacart is the leading grocery technology company in North America, partnering with more than 1,500 national, regional, and local retail banners to deliver from more than 85,000 stores across more than 14,000 cities in North America. To read more Instacart posts, you can browse the company blog or search by keyword using the search bar at the top of the page. Building Instacart Meals
Building Instacart Meals  7 steps to get started with large-scale labeling
7 steps to get started with large-scale labeling 

Most Recent in How It's Made

How It's Made
One Model to Serve Them All: How Instacart deployed a single Deep Learning pCTR model for multiple surfaces with improved operations and performance along the way
Authors: Cheng Jia, Peng Qi, Joseph Haraldson, Adway Dhillon, Qiao Jiang, Sharath Rao Introduction Instacart Ads and Ranking Models At Instacart Ads, our focus lies in delivering the utmost relevance in advertisements to our customers, facilitating novel product discovery and enhancing…
Dec 19, 2023
How It's Made
Monte Carlo, Puppetry and Laughter: The Unexpected Joys of Prompt Engineering
Author: Ben Bader The universe of the current Large Language Models (LLMs) engineering is electrifying, to say the least. The industry has been on fire with change since the launch of ChatGPT in November of…
Dec 19, 2023
How It's Made
Unveiling the Core of Instacart’s Griffin 2.0: A Deep Dive into the Machine Learning Training Platform
Authors: Han Li, Sahil Khanna, Jocelyn De La Rosa, Moping Dou, Sharad Gupta, Chenyang Yu and Rajpal Paryani Background About a year ago, we introduced the first version of Griffin, Instacart’s first ML Platform, detailing its development and support for end-to-end ML in…
Nov 22, 2023