How It's Made
From Postgres to Amazon DynamoDB 

Authors: Andrew Tanner, Manas Paldhe, Stefan Wild, Tristan Fletcher
Instacart is the leading online grocery company in North America. Users can shop from more than 75,000 stores with more than 500 million products on shelves. We have millions of active users who regularly place multiple orders with tens of items in their cart every month. To serve the growing user base and their needs, we have to efficiently store and query hundreds of terabytes of data. Our primary datastore of choice is Postgres, and we have gotten by for a long time by pushing it to its limits, but once specific use cases began to outpace the largest Amazon EC2 instance size Amazon Web Services (AWS) offers, we realized we needed a different solution. After evaluating several other alternatives, we landed on Amazon DynamoDB being the best fit for these use cases. In this post, we will talk through how we migrated some of our existing tables from Postgres to DynamoDB.
Notifications: Our first use case
Instacart leans heavily on push notifications to communicate with both our shoppers and our customers. Shoppers want to know about new batches of orders available as soon as possible so that they can maximize their earnings opportunities. They also want to be informed immediately after a customer updates an order so that the shopper can pick up the new items added to their cart. Similarly, customers want to know instantly if items they originally selected are not in stock so that they can choose the correct replacements and communicate with the shopper about those changes.
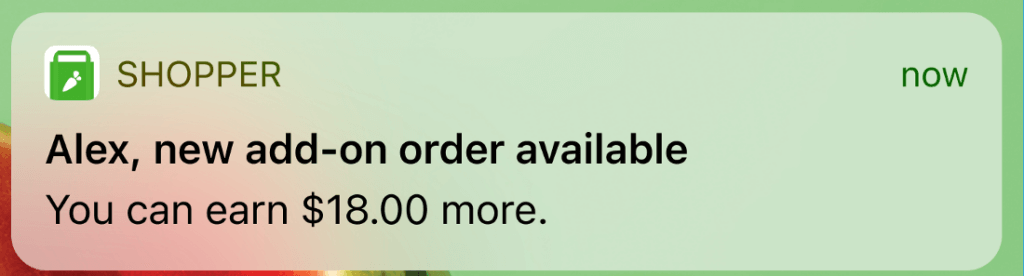

Initially, we used Postgres to store the state machine around messages sent to a user. The number of notifications sent increases linearly with the number of shoppers and customers on the platform. With a few features planned for release, we were projecting to send 8x more notifications every day than our baseline! We knew that as we continued to scale, a single Postgres instance would not be able to support the required throughput. We would have had to shard the Postgres cluster to accommodate the data there. Furthermore, we send more messages during the day when people are getting their deliveries, and very few during the night, so with a Postgres cluster we would have to pay for all that extra capacity, even at night when only a few push notifications are sent out. The ability to scale on-demand would be a plus to general cost efficiency as well as our ability to test and launch future features that change the volume of messages sent dramatically. Thus, we need to support a significant scale and to scale the capacity elastically when required, making this a perfect use case for DynamoDB!
Adapting the data model for DynamoDB
Based on the SLA guarantees and existing literature, we were confident that DynamoDB would fulfill our latency and scaling requirements. But cost was a concern.
Whenever you’re analyzing a cost tradeoff, you need to be crystal clear about what you’re comparing against. For this situation, the alternative would have been a sharded Postgres solution. The cost estimation for Postgres was fairly simple. We estimated the size per sharded node, counted the nodes and multiplied it by the cost per node per month.
In order to optimize for cost, we first have to understand how DynamoDB charges us. DynamoDB cost is based on the amount of data stored in the DynamoDB table, and the number of reads and writes to it. Storage is simple to estimate if you know how much data you have, as it costs about 25 cents for every GB stored during the month. Usage cost is a bit more complex to estimate. You can “pay-per-request”, but with lots of requests that becomes prohibitively expensive fast. If you can estimate how many reads and writes your table will receive, you can choose “provisioned capacity,” which is analogous to paying for a certain rate limit for reads and writes. We use the provisioned-capacity mode and autoscale the capacity up and down to maintain a comfortable headroom. A Read Capacity Unit (RCU) is the way AWS models the rate limit for “fetching data.” One-half of a RCU is consumed for an eventually-consistent row read that is smaller than 4KB in size. Similarly, Write Capacity Units (WCUs) represent the “setting data” request rate limit. One WCU is consumed for every write where the row size is smaller than 1KB. Another WCU is consumed for every index created on the table. It is important to note that RCUs and WCUs do not have the same price tag associated with them. WCUs cost about 10 times as much as RCUs. Therefore, the cost depends primarily on your data model and how the table is accessed.
First we analyzed the existing data and queries there and analyzed the cost of a direct translation to DynamoDB. For this use case, we have to create and deliver millions of messages every day. We already knew a few important details that would become very relevant to how we architect in DynamoDB. The first was about the size of the data. Metadata about the messages is stored as a large JSON object. In terms of raw size, about 75% of the rows were over 1 KB. The second was fetching the stored notifications. Users sometimes look up the past messages and hence we have to store them in the database for 7 days.
The table storing this data is write heavy, i.e. most of the load was from inserts and updates. In particular, the typical message lifecycle has 3 updates to move through its different states. Since these records are each over 1 KB, they would consume at least 2 DynamoDB Write Capacity Units (WCUs) for each write. These updates occurred on the primary key of a UUID, though reads flowed through an index in Postgres on the recipient of the notification. Hence, DynamoDB would have required a global secondary index (GSI) on the recipient to support the read access pattern. This would have incurred another WCU for that secondary index. Expressed as an equation for capacity, it looks like this:
2 WCU per item * (1 create + 3 updates)
+1 WCU for GSI (with KEYS_ONLY projection)
= 9 WCU per record lifecycle
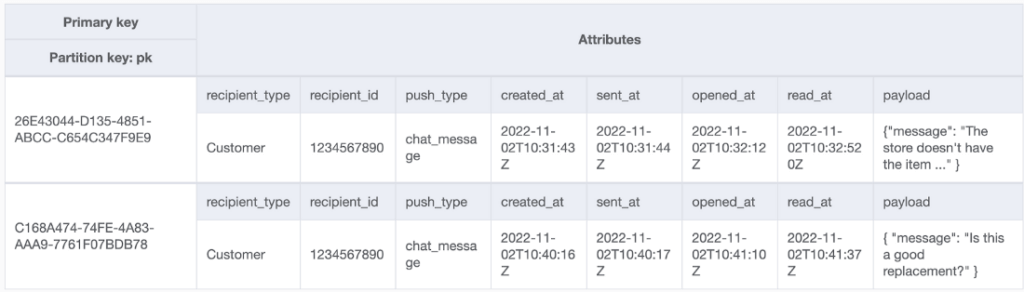
We knew this was inherently inefficient, as we were only really updating a single field in the object on each update, so in an attempt to avoid consuming 2 WCUs for each timestamp update, we followed the popular single table design pattern. We split each record into two parts. They both shared the same partition key (the UUID), but had different sort keys. The first just stores the JSON object as an attribute, while the second holds all of the timestamps and metadata. The table below shows this schema.
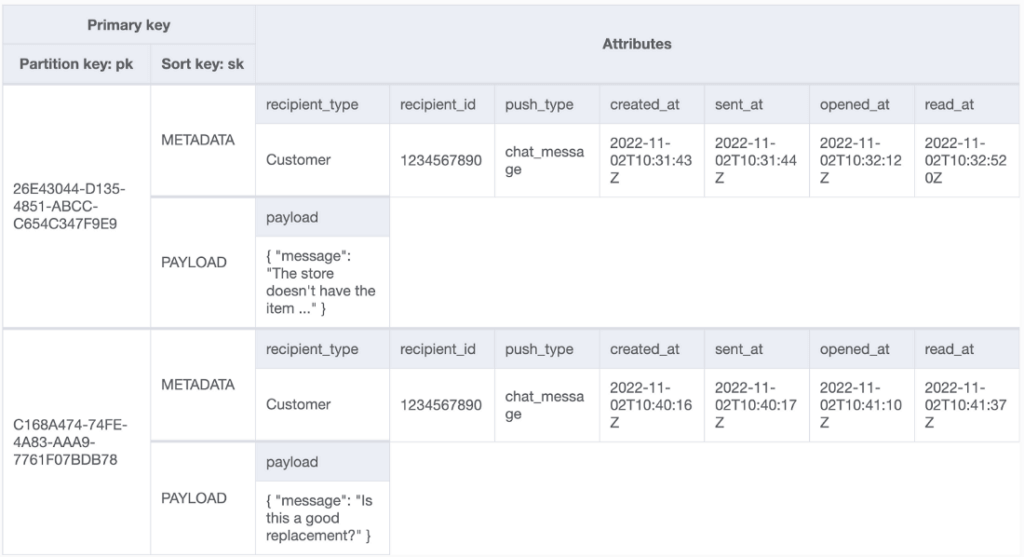
That reduced the expected capacity requirement by 2 WCUs per record lifecycle, as you can see here:
3 WCU to create a record (1 WCU for the metadata item + 2 WCU for the item containing the > 1KB JSON object)
+ 1 WCU for GSI
+ 3 WCU for 3 updates (metadata item only)
= 7 WCU per record lifecycle
Though this was a step in the right direction, it made reading non-trivial because the record would be split in multiple rows. Also, in practice the index would always be written yet rarely be read, and since writes are 10x the cost of reads, this felt suboptimal. Clearly, there was room for further optimization. We went back to the drawing board; this time thinking harder about our read pattern. Could we reduce the data size and get rid of the GSI if we changed the way the data was read?
Regarding the data size, the largest part of the message by far was the JSON field. GZip is known to have a high compression ratio for JSON, so we gave it a shot. Our experiments showed that GZip could compress the data to smaller than 1KB in size more than 99% of the time. This was a clear win in simplicity and scale compared to storing the payload record.
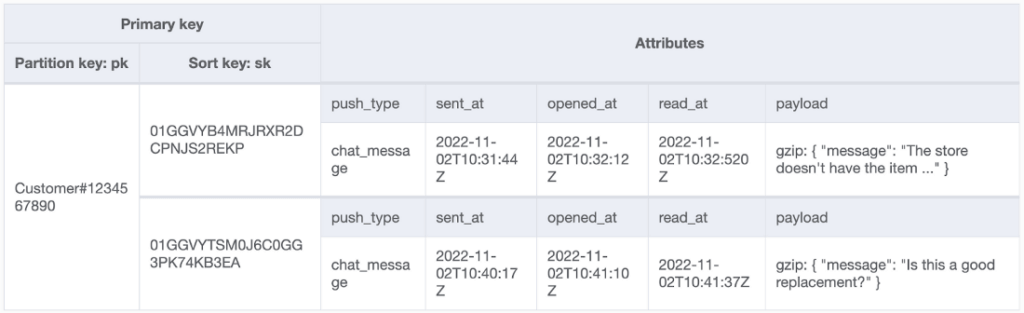
Next, we wondered whether we could make the primary key more useful, and remove the need for any global secondary index. As mentioned in our direct translation example, the primary key was arbitrary and used for updates whereas the read use case relied on an index of the recipient. We realized that we can use the recipient as the partition key. The recipient field would be the concatenation of userID and userType. Since one recipient receives many notifications, this key is not unique. Hence, we needed to use a range key as well. The combination of partition key and range key will be unique.
To serve the read requests, we need to easily fetch the most recent push notifications for a recipient. So, for the range key, we needed the values to be time-sortable. Initially we considered a pure epoch timestamp for the range key. This can potentially run into the corner case when a recipient gets multiple notifications at the same time. Hence, we wanted something with a uniqueness guarantee. ULIDs are time sorted and unique, and thus were a natural fit for the range key.

Now we could query on the partition key and filter the range key for time for our bulk read operations, as opposed to building and leveraging a GSI. The logic for updates did have to change, as the data no longer had a single unique key, it had a composite key of the partition and range key. However, this was a fairly trivial change to make to the update jobs, just give them the new key instead of the old one, and it resulted in a big savings as you can see here:
1 WCU * (1 Insert)
+1 WCU * (3 Updates)
= 4 WCUs per record lifecycle!
Rollout
Having optimized the schema for notifications, we started the implementation. One of the major blockers for using a new technology is ease of integration. To help developers smoothly transition from Postgres to DynamoDB, we elected to thinly wrap an open source library (Dynamoid) that exposed a similar interface to the ActiveRecord, to which they were already accustomed. We didn’t want to leave the team that owned the service with something they couldn’t understand, which can easily happen when changing to a different storage technology, so maintaining that ActiveRecord API made everything easier for the team to adopt and maintain going forward.
Wrapping Dynamoid also allowed us to include the tools that made this rollout successful i.e. field compression, time sorted identifiers, and compound partition keys in a simple API. We anticipated that these tools will also be used for future use cases. We rolled out dual writing and hid reading behind a feature flag. Conveniently, we only needed seven days of retention, so after a week, we began to slowly ramp up the reading switch. The rollout proceeded smoothly, and a week after the launch, we removed the Postgres codepath and downsized the Postgres database.
Conclusion
The goal of this project was to implement a trailblazer project to internally demonstrate the benefits of DynamoDB and provide Instacart engineers with an alternative to Postgres. In the course of transitioning this one system we learned a lot of important pieces to making a successful rollout. We learned how to design a good schema and primary key in order to use DynamoDB cost-effectively, and we learned what aspects of the workload and query patterns we needed to understand to make that good design. Teaching this knowledge to the application team helps them to produce a thoughtful design, which ultimately reduces the cost and improves application performance fleet-wide! This expertise has now become one of the biggest value-adds that we regularly provide to teams adopting DynamoDB.
In real terms, the specific design for the push notifications service, not only solved our scaling issues, but also helped us in cutting our costs by almost half.
The tools and support systems that we built led to more teams using DynamoDB. Features related to Ads, Offers sent to customers, Instacart Plus, etc are now powered by DynamoDB. In just the past 6 months we have grown from 1 to more than 20 tables, supporting 5–10 different features across different organizations!
All these new use cases didn’t come without their own new requirements though. In our next post on DynamoDB, we’ll talk about how we built tools around ETL and developer enablement in order to remove more barriers to DynamoDB adoption at Instacart. This is just the beginning of DynamoDB adoption at Instacart!
Instacart
Author
Instacart is the leading grocery technology company in North America, partnering with more than 1,500 national, regional, and local retail banners to deliver from more than 85,000 stores across more than 14,000 cities in North America. To read more Instacart posts, you can browse the company blog or search by keyword using the search bar at the top of the page. Building Instacart Meals
Building Instacart Meals  7 steps to get started with large-scale labeling
7 steps to get started with large-scale labeling 

Most Recent in How It's Made

How It's Made
One Model to Serve Them All: How Instacart deployed a single Deep Learning pCTR model for multiple surfaces with improved operations and performance along the way
Authors: Cheng Jia, Peng Qi, Joseph Haraldson, Adway Dhillon, Qiao Jiang, Sharath Rao Introduction Instacart Ads and Ranking Models At Instacart Ads, our focus lies in delivering the utmost relevance in advertisements to our customers, facilitating novel product discovery and enhancing…
Dec 19, 2023
How It's Made
Monte Carlo, Puppetry and Laughter: The Unexpected Joys of Prompt Engineering
Author: Ben Bader The universe of the current Large Language Models (LLMs) engineering is electrifying, to say the least. The industry has been on fire with change since the launch of ChatGPT in November of…
Dec 19, 2023
How It's Made
Unveiling the Core of Instacart’s Griffin 2.0: A Deep Dive into the Machine Learning Training Platform
Authors: Han Li, Sahil Khanna, Jocelyn De La Rosa, Moping Dou, Sharad Gupta, Chenyang Yu and Rajpal Paryani Background About a year ago, we introduced the first version of Griffin, Instacart’s first ML Platform, detailing its development and support for end-to-end ML in…
Nov 22, 2023