How It's Made
Griffin: How Instacart’s ML Platform Tripled ML Applications in a year
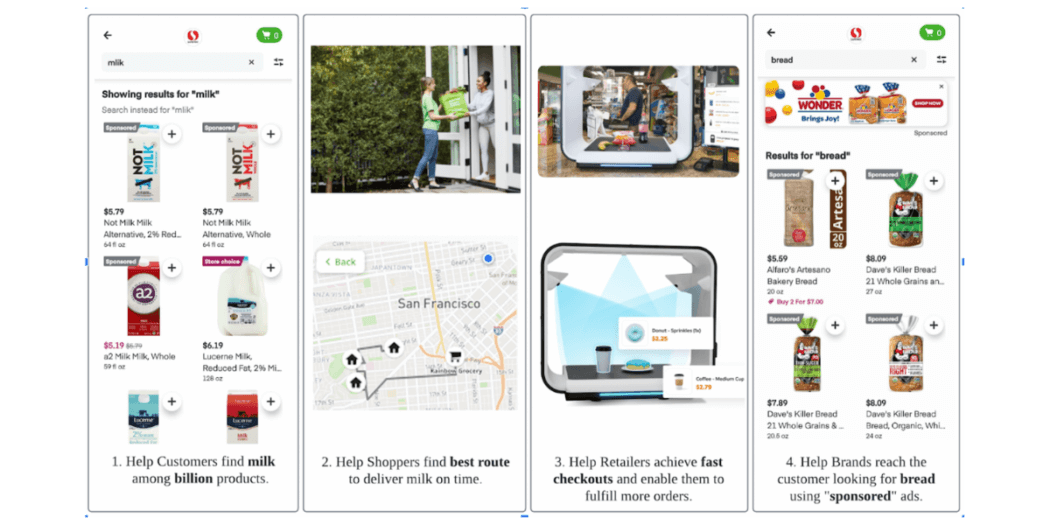
Instacart’s hyper-growth entails increasing machine learning applications and requires fast iterations of machine learning workflows.
To meet these requirements, we built Griffin, an extensible platform that supports diverse data management systems, integrates with multiple machine learning tools, and various machine learning workflows. This post introduces MLOps at Instacart, outlines Griffin system design, and shares our learnings in building Griffin to empower product innovations at Instacart.
Author: Sahil Khanna, Machine Learning Engineer
Machine Learning Operations (MLOps) at Instacart
Machine learning plays a critical role in powering the Instacart experience. ML is the basis of nearly every product and operational innovation at the company, and we rely on this technology to navigate challenges of tremendous scale every day. Machine learning:
- Helps customers find the right items in a catalog of over 1 billion products.
- Supports 600,000+ shoppers to efficiently deliver products to millions of customers in the US and Canada.
- Brings artificial intelligence into the Instacart platform to support 800+ retailers across 70,000+ stores in 5,500+ cities in the US and Canada.
- Enables 5,000+ brand partners to connect their products to potential customers.
Each of these use cases can require multiple machine learning models that must seamlessly integrate to power the end-to-end experience. Griffin, built by the machine learning infrastructure team at Instacart, plays a foundational role to support these machine learning applications and empower product innovations.
Evolution of MLOps Platform – from Lore to Griffin
We started developing machine learning infrastructure in 2016 with our open-sourced machine learning framework, Lore. Lore enabled machine learning engineers (MLEs) to develop and train ML models without dealing with system details. For example, it abstracted away connections to data sources (such as Postgres and Snowflake), managed development environments for python applications, supported modeling using open-source frameworks (Keras, Scikit-learn, XGBoost), and integrated simple feature engineering in the model. When we only had a few machine learning applications at Instacart, Lore fulfilled our requirements and enabled us to deploy ML applications in production quickly. However, as our company has grown, there has been an increase in the number, diversity, and complexity of machine learning applications. Lore became a bottleneck because of its monolithic architecture, and to accommodate new features, we had to refactor Lore’s core design. To address this problem, we built Griffin, an extensible and self-serving machine learning platform, based on microservice architecture using a hybrid solution.
Hybrid Solution for MLOps
Machine learning has a broad spectrum of fields, where various machine learning systems and tools are built for different application scenarios. For instance, MLFlow manages metadata and artifacts of the models, Ray/Kubeflow automates ML training and serving, and Feast manages ML features. Companies like Shopify and Spotify have adopted these tools for their MLOps platform, whereas companies like Netflix and Facebook have developed in-house solutions.
To leverage various tools and satisfy diversified machine learning requirements, we adopted a hybrid solution for MLOps at Instacart. We use a combination of third-party solutions (such as Snowflake, AWS, Databricks, and Ray) to support diverse use cases, and in-house abstraction layers to provide unified access to those solutions. This approach helps us deploy specialized and diverse solutions, and stay current with innovations in the MLOps field.
Griffin: Instacart’s MLOps Platform
Griffin is developed to help MLEs (Machine Learning Engineers) quickly iterate on machine learning models, effortlessly manage product releases, and closely track their production applications. Based on these goals, we built the system with a few major system considerations:
- Scalability: The platform should support up to thousands of machine learning applications at Instacart.
- Extensibility: The platform should be flexible to extend and integrate with various data management backends and machine learning tools.
- Generality: The platform should provide a unified workflow and consistent user experience despite its broad integration with third-party solutions.
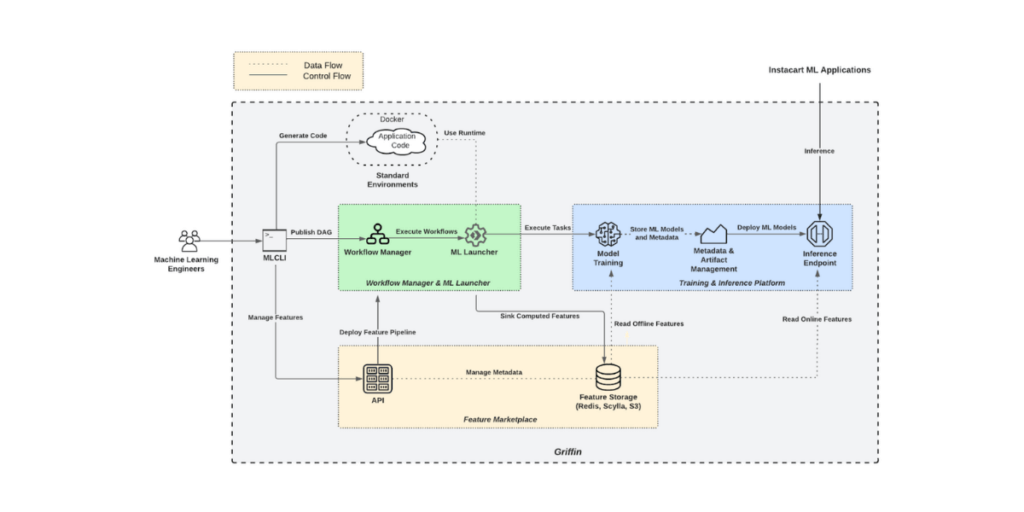
As shown in Figure 2, Griffin integrates multiple SaaS solutions (including Redis, Scylla, and S3) thereby enhancing features in the platform (extensibility), supporting ML growth at Instacart (scalability), and providing a unified interface for the MLEs (generality). The platform includes four foundational components: an interface to use the platform (MLCLI), an orchestrator to schedule pipelines (Workflow Manager & ML Launcher), a data platform to manage features (Feature Marketplace), and a computing platform to run the jobs (Training & Inference platform). These components are distinct elements of our extensible platform, enabling us to develop specialized solutions for different use cases such as real-time recommendations.
MLCLI
MLCLI is our in-house machine learning interface to develop machine learning applications and manage model lifecycle.
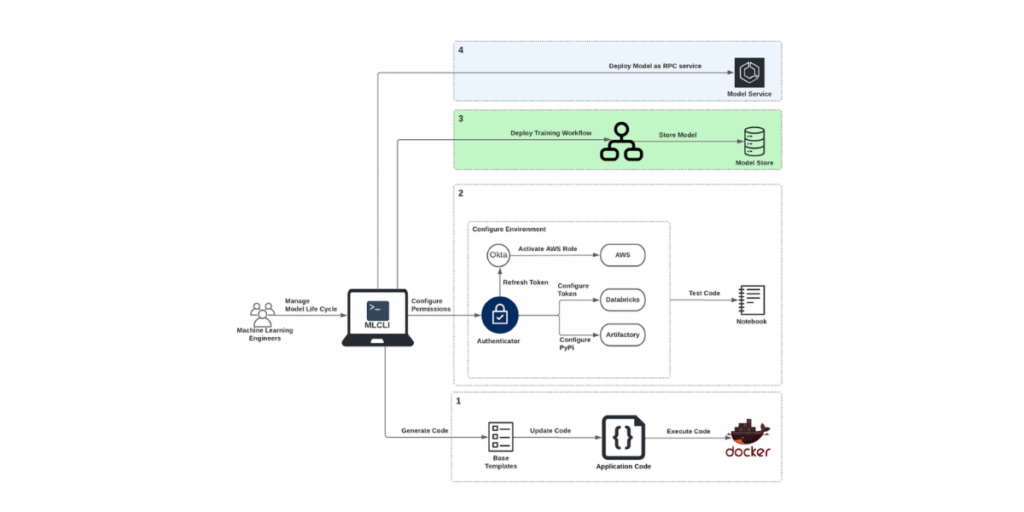
MLCLI enables MLEs to customize tasks like training, evaluation, and inference in their applications and execute these tasks within containers (including, but not limited to, Docker). This eliminates issues caused by differences in the execution environment and provides a unified interface. To develop an ML model, put it in production, and monitor it, our MLEs:
- Generate ML workflow code from base templates and update the code of their application.
- Test code using Notebooks.
- Deploy an ML workflow for feature engineering and continuous training of the ML model.
- Host the trained ML model as an endpoint for inference.
Workflow Manager & ML Launcher
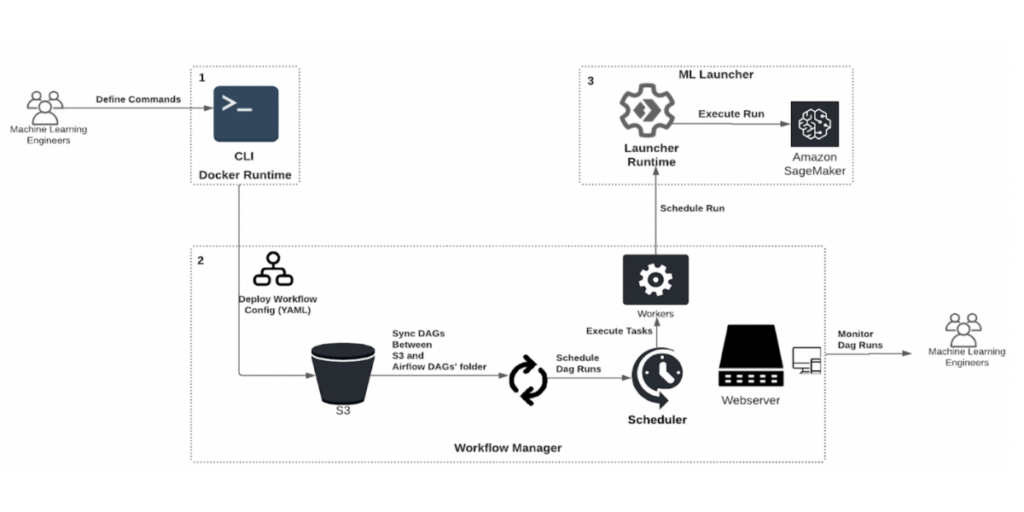
Workflow Manager schedules and manages machine learning pipelines. It leverages Airflow to schedule containers and utilizes an in-house abstraction – ML Launcher – to containerize task execution. ML Launcher integrates compute backends like Sagemaker, Databricks, and Snowflake to perform container runs and meet the unique hardware requirements for ML such as GPUs, instances with large memory, and disks with high IO throughput. This design choice enables MLEs to develop and deploy pipelines without worrying about Airflow runtime and allows us to scale easily to hundreds of DAGs (Directed Acyclic Graphs) with thousands of tasks in a short period. When deploying an ML pipeline, MLEs:
- Define each step of the workflow as an independent command in a Docker runtime.
- Construct and deploy workflow for execution.
- All-new workflows are automatically synchronized, scheduled, and executed for continuous training.
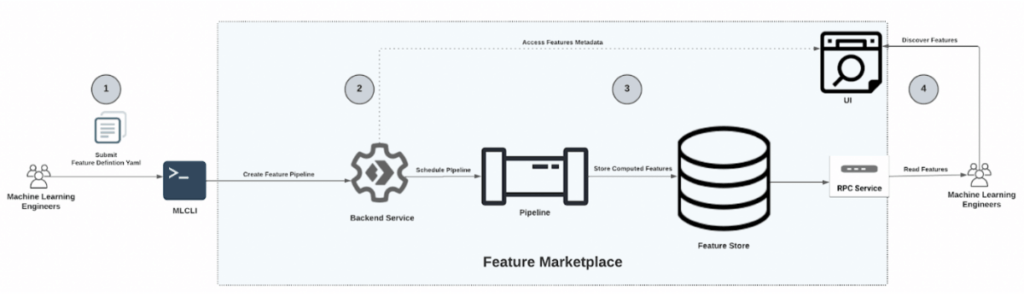
Feature Marketplace
Data is at the center of the modern MLOps platform. We have developed an FM (Feature Marketplace) product that uses platforms such as Snowflake, Spark, and Flink to support real-time and batch feature engineering. It manages feature computation, provides feature storage, enables feature versioning, supports feature discoverability, eliminates offline/online feature drift, and allows feature sharing. Following our hybrid solution to integrate multiple storage backends (Scylla, Redis, and S3), we have balanced latency and storage costs for serving features at scale.
To define new features for the ML models, MLEs:
- Define an FD (Feature Definition), a standard schema to define features in YAML.
- After defining the feature computation logic in FD, the MLE sends an API request to the FM backend service, a microservice to manage CRUD operations on feature pipelines.
- Backend service schedules pipelines to compute features on a regular cadence specified in the FD and index the computed features in Feature Store, a storage layer to provide consistent access to features.
- Once the indexing is complete, MLEs can discover features using FM UI and consume features using RPC service.
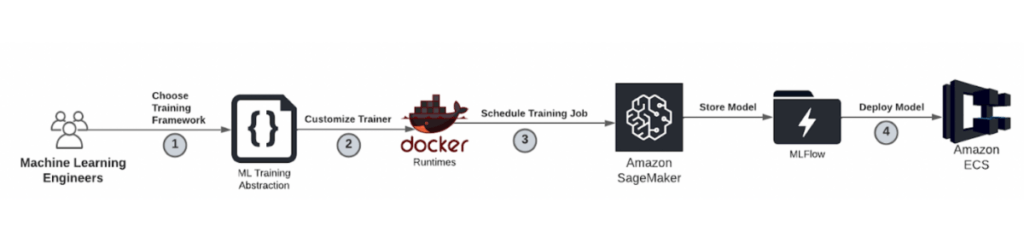
Inference & Training Platform
We developed a framework-agnostic training and inference platform to adopt open-source frameworks like Tensorflow, Pytorch, Sklearn, XGBoost, FastText, and Faiss. To support the diversity in frameworks and to ensure reliable model deployment in production, we standardize package management, metadata management, and code management. The platform allows MLEs to define the model architecture and inference routine to customize their applications enabling us to triple the number of ML applications in one year. The typical user workflow for using the training and inference platform entails:
- MLEs begin the development by choosing the training framework supported in ML Training Abstraction, a Python package that defines classes for training management.
- They then update the trainer class to build a custom model network and Docker runtime for their applications.
- Using Docker runtimes, they tune the hyperparameter by scheduling multiple runs and tracking the metrics/metadata in the MLFlow.
- They deploy the model version with the best performance based on offline metrics to the inference service using Twirp (an RPC framework) and AWS ECS (a managed container orchestration service).
Lessons Learned
When we look back at our journey in building Griffin to support ML growth, we derived a few key learnings.
- Buy Vs Build. Leveraging existing commercial/non-commercial third-party solutions enabled us to support a quickly-growing feature set and avoid reinventing the wheel. It was critical to carefully integrate these solutions into the platform so that we can switch between solutions with minimal migration overheads.
- Make it flexible. Supporting custom ML applications increased adoption among diverse teams at Instacart. We generated code from the standardized template providing the ability to override, and allowed MLEs to integrate legacy systems until they had the bandwidth for migration. To ensure a consistent running environment for custom applications, we adopted Docker runtimes which simplify reproducing users’ experiences and allow us to troubleshoot issues more quickly.
- Make incremental progress. Regular onboarding sessions streamlined feedback and kept the platform design simple. We scheduled regular hands-on codelabs to onboard MLEs onto the new features and get early feedback for further improvement. It encouraged collaborations and enabled us to prevent engineers from getting into the rabbit hole of spending years building the ‘perfect’ platform.
- Extensibility enables rapid growth. Extensible and reusable foundational components helped us build a self-service infrastructure for accommodating feature requests from growing MLEs, a modular codebase for adapting to the fast-changing landscape, a simple interface for smooth onboarding, and a production-ready system for scaling to millions of Instacart users.
Instacart
Author
Instacart is the leading grocery technology company in North America, partnering with more than 1,500 national, regional, and local retail banners to deliver from more than 85,000 stores across more than 14,000 cities in North America. To read more Instacart posts, you can browse the company blog or search by keyword using the search bar at the top of the page. Building an Essential Service During a Pandemic
Building an Essential Service During a Pandemic  Building for Balance
Building for Balance  Catalog Localization: more than just a translation!
Catalog Localization: more than just a translation!  Designing Digital Experiences That Augment the Analog World
Designing Digital Experiences That Augment the Analog World 

Most Recent in How It's Made

How It's Made
One Model to Serve Them All: How Instacart deployed a single Deep Learning pCTR model for multiple surfaces with improved operations and performance along the way
Authors: Cheng Jia, Peng Qi, Joseph Haraldson, Adway Dhillon, Qiao Jiang, Sharath Rao Introduction Instacart Ads and Ranking Models At Instacart Ads, our focus lies in delivering the utmost relevance in advertisements to our customers, facilitating novel product discovery and enhancing…
Dec 19, 2023
How It's Made
Monte Carlo, Puppetry and Laughter: The Unexpected Joys of Prompt Engineering
Author: Ben Bader The universe of the current Large Language Models (LLMs) engineering is electrifying, to say the least. The industry has been on fire with change since the launch of ChatGPT in November of…
Dec 19, 2023
How It's Made
Unveiling the Core of Instacart’s Griffin 2.0: A Deep Dive into the Machine Learning Training Platform
Authors: Han Li, Sahil Khanna, Jocelyn De La Rosa, Moping Dou, Sharad Gupta, Chenyang Yu and Rajpal Paryani Background About a year ago, we introduced the first version of Griffin, Instacart’s first ML Platform, detailing its development and support for end-to-end ML in…
Nov 22, 2023