How It's Made
Personalizing Recommendations for a Learning User

A talk by Prof. Hongning Wang as part of Instacart’s Distinguished Speaker Series
Co-authored by Haixun Wang and Jagannath Putrevu
Recommendation systems are at the heart of Instacart: we want to surface the most appropriate products to customers to ensure the best shopping experience. However, while we are learning about customers, customers might also simultaneously be learning about their own preferences while interacting with Instacart. This dynamic makes personalized recommendations a more challenging task because customers may change their preferences as they view more recommendations. As part of Instacart’s Distinguished Speaker series, we had the pleasure of hosting Professor Hongning Wang of the University of Virginia, who provided an elegant solution to this challenge.
In this setting, the recommendation problem is framed as a multi-armed bandit problem, and the goal is to identify the best arm (canonically known as the best arm identification problem, or BAI). Depending on the context of the problem, an arm can be a whole category of items (e.g., dairy products), or an algorithm, or each item that is recommended. Accordingly, one needs to define the outcomes from “pulling the arm”, for example, the presented category is clicked (i.e., accepted) by the user. The key difference to a classical multi-armed bandit setting is that: in this framework, 1) the user updates their utility estimation on rewards from their accepted recommendations; and 2) the user withholds the rewards from the recommendation system, but only reveals the binary accept/reject decisions. As such, the user under this model is constantly learning, with the help of the recommendation system.
The interaction between the user and the system is sequential: the users can only refine their reward estimation of an arm if the recommendation system presents the arm to them; and the system can only learn the user’s preference from the user’s revealed binary accept/reject response. We assume the user is rational: they maintain a confidence interval on reward of each arm, which is updated after each interaction. An arm will be rejected if its upper confidence bound is lower than at least another arm’s lower confidence bound (as shown in Figure 1). While these constraints are more inline with reality, they also make the learning problem harder. To this end, Professor Wang and his team have devised an elegant algorithm that, requiring only some more attempts, is capable of identifying the best arm.
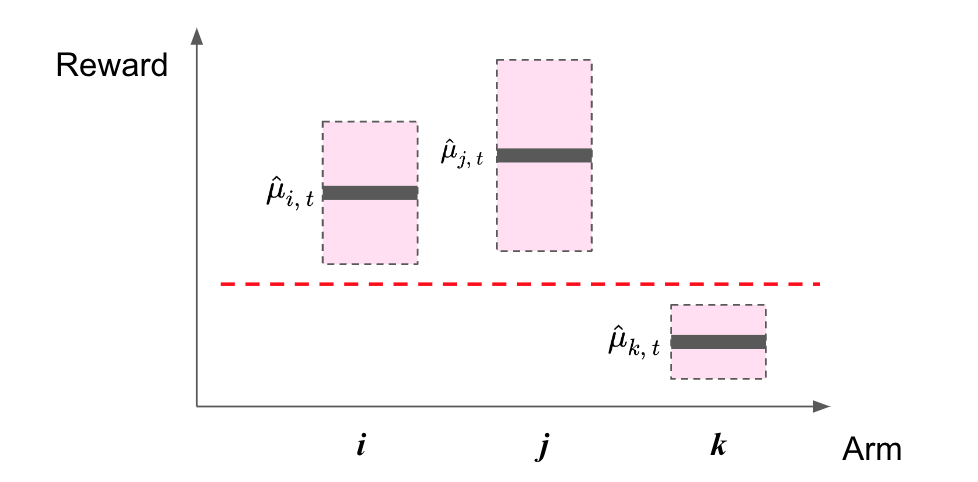
This algorithm, best arm identification under revealed preference (BAIR), works in two phases. In Phase-1 (dubbed as “sweeping”), the recommendation system will present all the arms to the users, if an arm is rejected by the user, the system will remove it from future recommendations. This is in contrast to standard bandit algorithms where one aims to have each arm accepted at least once. The sweeping strategy reflects the principle during this phase: the system aims to collect a reasonable number of acceptances while minimizing the number of rejections by not recommending any risky arm. The system also sets a total number of interactions in Phase-1, and is determined by false positive rate: the lower the chance to identify the wrong best-arm, the more interactions are required. In Phase-2 (dubbed as “elimination”), the system always recommends the arm with the minimum number of acceptances; and eliminates an arm when it is rejected by the user, until there is only one arm left. For example, if algorithms are treated as arms, one can define rejection as insufficient clicks or purchases.
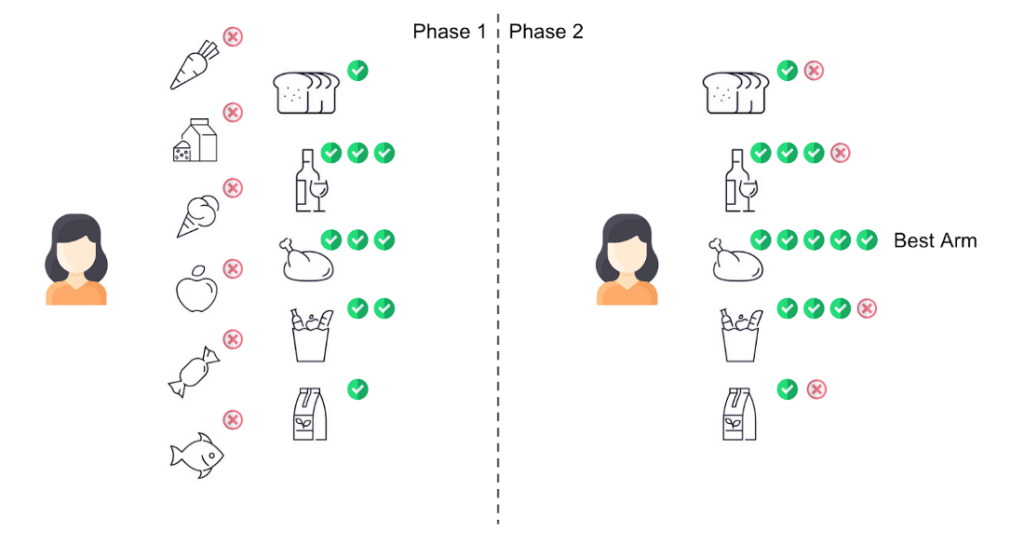
How effective is this algorithm? To answer this question, Professor Wang’s team conducted numerical simulations to compare BAIR with three existing algorithms: none of them can achieve the same efficiency or accuracy of BAIR. The fundamental reason for the failure of these algorithms lies in the insufficient system exploration when facing an explorative user. These algorithms either treat the user as a black-box, or assume independent and stationary user feedback which leads to a worse empirical result. In contrast, BAIR is aware that the revealed preferences from the early stage are very likely to have a large variance. Therefore, it chooses to make safe recommendations at first in order to help the user gain more experiences (Phase-1 exploration) such that the user will reveal more accurate feedback later on (Phase-2 elimination).
This more realistic modeling of user behavior (the user is also learning their own utility) poses both a challenge and an opportunity for the modern recommendation system. The BAIR algorithm addresses this challenge head-on and provides a tractable solution: it can identify the best arm with the probability of 1 − δ within O(1/δ) interactions. In this way, we can continue serving the highest quality recommendation to the customer as they are gradually shaping their own preferences.
About Instacart’s Distinguished Speaker Series: started in 2021, Instacart’s Distinguished Speaker series is a public forum where researchers in the fields of Machine Learning, Economics, Computer Science are invited to present their recent works. Past speakers include renowned researchers from institutes such as Stanford and UC Berkeley.
Reference: [2110.03068] Learning the Optimal Recommendation from Explorative Users
Instacart
Author
Instacart is the leading grocery technology company in North America, partnering with more than 1,500 national, regional, and local retail banners to deliver from more than 85,000 stores across more than 14,000 cities in North America. To read more Instacart posts, you can browse the company blog or search by keyword using the search bar at the top of the page. Building Instacart Meals
Building Instacart Meals  7 steps to get started with large-scale labeling
7 steps to get started with large-scale labeling 

Most Recent in How It's Made

How It's Made
One Model to Serve Them All: How Instacart deployed a single Deep Learning pCTR model for multiple surfaces with improved operations and performance along the way
Authors: Cheng Jia, Peng Qi, Joseph Haraldson, Adway Dhillon, Qiao Jiang, Sharath Rao Introduction Instacart Ads and Ranking Models At Instacart Ads, our focus lies in delivering the utmost relevance in advertisements to our customers, facilitating novel product discovery and enhancing…
Dec 19, 2023
How It's Made
Monte Carlo, Puppetry and Laughter: The Unexpected Joys of Prompt Engineering
Author: Ben Bader The universe of the current Large Language Models (LLMs) engineering is electrifying, to say the least. The industry has been on fire with change since the launch of ChatGPT in November of…
Dec 19, 2023
How It's Made
Unveiling the Core of Instacart’s Griffin 2.0: A Deep Dive into the Machine Learning Training Platform
Authors: Han Li, Sahil Khanna, Jocelyn De La Rosa, Moping Dou, Sharad Gupta, Chenyang Yu and Rajpal Paryani Background About a year ago, we introduced the first version of Griffin, Instacart’s first ML Platform, detailing its development and support for end-to-end ML in…
Nov 22, 2023