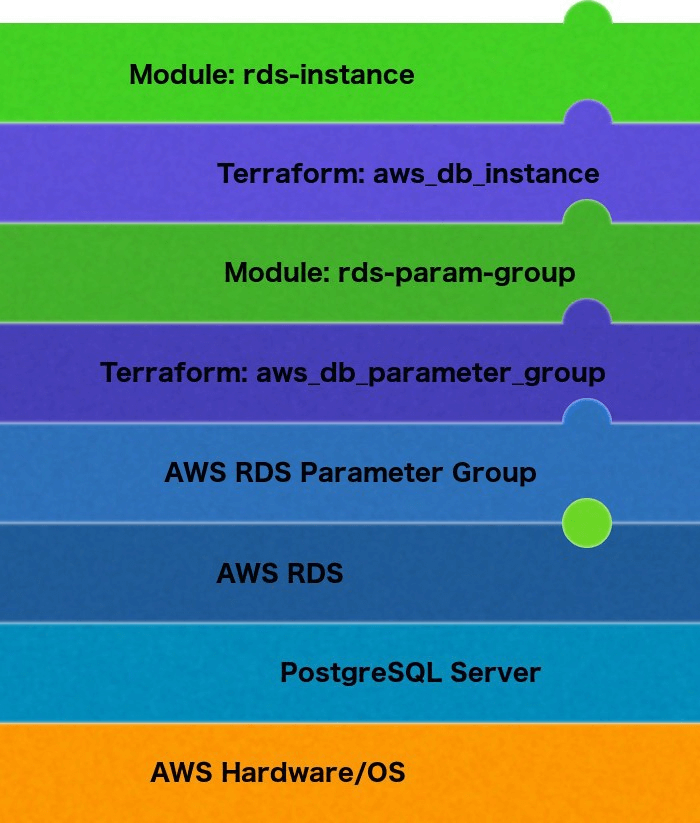
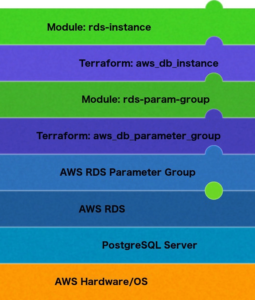
After the upgrade the CPU of the database started spiking on a regular basis, leading to significant problems in our application. It was all hands on deck, including AWS support, trying to diagnose the problem. Obviously, the changes we’d made to the parameter group were suspect, so we reverted it, using the Terraform for the 9.6 parameter group, back to exactly what it had been before.
The problems persisted.
After days of investigation, updates and reverts of parameters, and ongoing CPU spikes, someone said:
IMO we need a way to diff postgres configs directly, not just RDS parameter group settings
pg_settings
It occurred to me that we could compare the actual settings by looking directly in the database, so I poked around quickly and found this query:
select name, setting, unit from pg_settings;
This allowed me to pull all the parameter values from both an old copy of the original database and the new database. A quick sort and diff and I saw that one of the parameters was max_wal_size, which was set to 128in both databases, just as we specified in the parameter group resource:
parameter {
apply_method = "immediate"
name = "max_wal_size"
value = "128"
}
The units column, however, was different. In the PostgreSQL 9.6 instance:
postgres=> select name, setting, unit from pg_settings where name = 'max_wal_size'; name | setting | unit --------------+---------+------ max_wal_size | 128 | 16MB (1 row)postgres=> show max_wal_size; max_wal_size -------------- 2GB (1 row)
In the PostgreSQL 10 instance:
postgres=> select name, setting, unit from pg_settings where name = 'max_wal_size'; name | setting | unit --------------+---------+------ max_wal_size | 128 | MB (1 row)postgres=> show max_wal_size; max_wal_size -------------- 12MB (1 row)
This is very different. With the “same” setting, but a unit of 1 megabyte, the entire max_wal_size is 128 megabytes, 1/16th of what we expected it to be.
RTFM
We went back and looked at the AWS documentation. It did not say anything about a change to the units being used for this parameter. We put in a ticket for them to fix the docs. The response was that the docs would be fixed within a month 😬.
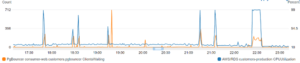
This explained the CPU spikes and all the other issues we were having — instead of checkpointing every 5–10 minutes, we were checkpointing more than once a minute! The combination of RDS and Terraform hid this change from us — we relied on the Terraform and believed that our settings were identical when they were not.
Want to work on challenges like these? Instacart is hiring!
Check out our current openings.

 Building Instacart Meals
Building Instacart Meals  7 steps to get started with large-scale labeling
7 steps to get started with large-scale labeling 



