How It's Made
The Story Behind an Instacart Order, Part 1: Building a Digital Catalog
By: Gordon McCreight
It’s 5:00 pm, you’re heading home from work, and want to make a quick dinner tonight by 7:30 pm. You want to cook up some salmon, but are missing three key ingredients in your fridge: 2.5 lbs of fresh salmon fillets, 1 Meyer lemon, 1 bunch of fresh dill. You pull up Instacart on your iPhone, add these three items to your cart, set your 6:00–7:00 pm delivery window, and complete your order. An hour and a half later, your groceries are delivered to your door right as you’re pre-heating the oven.
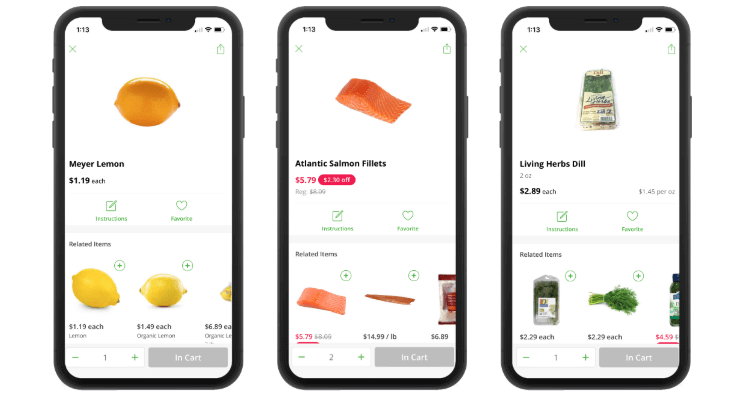
The moment is simple and satisfying on the surface, but beneath it all lies a complicated web of systems, working together to fulfill your order. In this “Journey of an Order” series, we’ll walk you through the technology that surfaces grocery items in our apps, enables storefront browsing, guides the shopper through checkout, and powers our last mile logistics to get dinner to your door in as fast as an hour.
In this first installment, we’ll dive into how we acquire grocery item attributes and inventory data from retail partners, configure locations and inventories in near real-time, and get data into a usable format in our larger grocery “catalog”.
Acquiring grocery data
Our catalog is the largest online grocery catalog in the world, with over half a billion item listings from over 300 different retailers from nearly 20,000 stores across North America.
At a minimum, any single product in our catalog has a subset of attributes: price, name, location, UPC, and SKU. We can accommodate a more detailed list of attributes, including multiple images, nutritional information, seasonality info, dietary labels (gluten-free, kosher, vegan, etc) — the more attributes we collect, the more flexible and fine-grained data taxonomy and search can be for our shoppers and customers down the line.
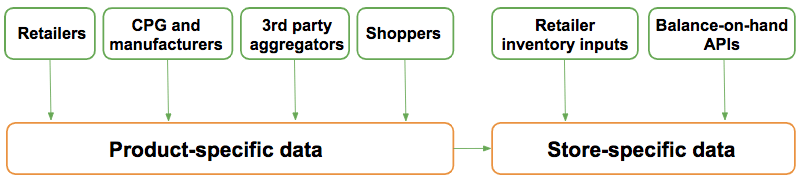
So, how do you acquire all this information? It requires working with many disparate sources of data of varying accuracy. Our catalog is made up of over 30 data sources, including data provided directly by a retailer, third-party content aggregator, manufacturer, and even “homegrown” collected in the field by Instacart shoppers and site managers.
We collect two levels of item attributes:
- Store-specific attributes: availability, specialty items tied to location, location-by-location pricing
- Product-specific attributes: name, product descriptions, approved photos, nutritional information, size/weight
Updating our catalog
Instacart updates more catalog data points every night than the world tweets in a day.
Inventory, prices and other attributes change minute by minute, if we don’t reflect those changes in our catalog, our storefronts don’t reflect accurate listings, resulting in disappointment from customers, shoppers, retailers, and CPG partners. From our early days working with just a handful of retailers, we’ve invested in tooling to enable them to send us regular updates about the products on their shelves. When the price of an item changes at a particular store location, or if the product becomes unavailable, retail partners can alert us in several ways depending on the size of their inventory and specifics of their own technical infrastructure.
For manual, one-off edits, we’ve built a user-friendly web portal with a form-fill that allows retailers to add in updated product attributes, at any time they choose.
We give retailers the option to drop CSV files on our SFTP server with updated product attributes. They can drop updates onto the SFTP server as often as they like — many choose to push it once daily.


Some retailers, often partners who’ve built sophisticated inventory systems in-house, are able to provide us with a real-time stream of “balance-on-hand” data, giving us moment-to-moment updates about items on their shelves. We’ve built out an API that retailers can use to send us changes in availability and product attributes in real-time.
Prioritizing data inputs
That’s the easy stuff. Once you have all of this data, how do you clean it? How do you determine the best, most accurate, and most consistent product attributes for listings in our catalog? Finding the most accurate attributes requires us to pit sources against each other, and prioritize inputs.
Product availability is a store-specific attribute that has a massive effect on our customer and shopper experience. If the data we received last night in a CSV file drop tells us that Meyer lemons are in stock at a store in Mobile, Alabama, but a shopper on the ground indicates in their app that the item is out of stock, we have to weigh each input against one another and make a split second decision about what input is correct.
We initially built a set of heuristics around this, comparing the reliability of data sources at a macro level to determine the “most accurate” answer to the question of whether the Meyer lemons are actually in the store. We used a bit of good old human intuition to create these heuristics. For example, multiple shoppers reporting an item is out of stock at a location is *usually* more reliable than a 3rd party provider’s data. One-off inputs given in the last 30 minutes through the retailer portal are *usually* more accurate than a nightly update via CSV. It can get more complicated, though. What if a shopper and a retail manager send conflicting inputs at the same time? At our scale, that happens.
Human intuition can only take you so far, however. We cooked up these heuristics when we had a lot fewer product listings in our catalog. Currently, we deal with much larger data ingests every day, and we have a lot more inputs coming from shoppers, brands and retailers. Now, we’re looking to machine learning models to find more signals from the noise and build better, more fine-grained prioritization models at scale. Ultimately building out these models gives us pinpoint accuracy, and makes it easier for you to see if your fresh Atlantic Salmon fillets are in-store, or if we’ll need to add 10–15 minutes to our dinner prep schedule to defrost a frozen salmon fillet replacement item.
Building for scale: catalog infrastructure
In 2018 alone, we on-boarded more than 100 new retailer partners, each with their own unique store and product-specific attributes
Our database infrastructure has traditionally evolved as an “artisanal” system, built over time to address our immediate needs as they came up. In short, it was never architected.
Keeping up with the daily mountain of data our partners send and dealing with data quality issues at scale, is one of the primary challenges for our Catalog team. Now with seven years of catalog data, and billions of data points updated every day, we recognized that we needed to build a system to handle “big data problems.”
Fun fact: While partners can send us inventory data at any point in the day, we receive most data dumps around 10 pm local time. Certain individual pieces of our system (like Postgres) weren’t configured to handle these 10 pm peak load times efficiently — we didn’t originally build with elastic scalability in mind. To solve this we began a “lift and shift” of our catalog infrastructure from our artisanal system to a SQL-based interface, running on top of a distributed system with inexpensive storage. We’ve decoupled compute from that storage, and in this new system, we rely on Airflow as our unified scheduler to orchestrate that work and Snowflake to store and query the data.
Rebuilding our infrastructure now not only helps us deal with load times efficiently, it saves cost in the long run and ensures that we can make more updates every night as our data prioritization models evolve.
Once we’re confident that the salmon fillet, fresh dill, and Meyer lemon attributes are the most accurate, up-to-date, and “best” listings we have, we surface that data into the online storefronts that our customers use every day. Stay tuned for the next installment of this series, where we’ll dig into the tech that makes our customer-facing app tick.
Can’t get enough of databases and library science 📚? Our Catalog team is hiring! Check out our current engineering openings.
*Learn more about Engineering at Instacart on our Tech blog.
Instacart
Author
Instacart is the leading grocery technology company in North America, partnering with more than 1,500 national, regional, and local retail banners to deliver from more than 85,000 stores across more than 14,000 cities in North America. To read more Instacart posts, you can browse the company blog or search by keyword using the search bar at the top of the page. Building Instacart Meals
Building Instacart Meals  7 steps to get started with large-scale labeling
7 steps to get started with large-scale labeling 

Most Recent in How It's Made

How It's Made
One Model to Serve Them All: How Instacart deployed a single Deep Learning pCTR model for multiple surfaces with improved operations and performance along the way
Authors: Cheng Jia, Peng Qi, Joseph Haraldson, Adway Dhillon, Qiao Jiang, Sharath Rao Introduction Instacart Ads and Ranking Models At Instacart Ads, our focus lies in delivering the utmost relevance in advertisements to our customers, facilitating novel product discovery and enhancing…
Dec 19, 2023
How It's Made
Monte Carlo, Puppetry and Laughter: The Unexpected Joys of Prompt Engineering
Author: Ben Bader The universe of the current Large Language Models (LLMs) engineering is electrifying, to say the least. The industry has been on fire with change since the launch of ChatGPT in November of…
Dec 19, 2023
How It's Made
Unveiling the Core of Instacart’s Griffin 2.0: A Deep Dive into the Machine Learning Training Platform
Authors: Han Li, Sahil Khanna, Jocelyn De La Rosa, Moping Dou, Sharad Gupta, Chenyang Yu and Rajpal Paryani Background About a year ago, we introduced the first version of Griffin, Instacart’s first ML Platform, detailing its development and support for end-to-end ML in…
Nov 22, 2023